Modelos e Algoritmos
Como prever onde as plantas podem viver
em um clima que muda?
Disciplina: Mudanças Climáticas
Engenharia Florestal - UDESC
Prof. Pedro Higuchi
Roteiro da aula
- O que são modelos e para que servem
- O que são algoritmos
- Por que modelar onde as espécies vivem?
- Como o computador "aprende" padrões
- O algoritmo Random Forest (Floresta Aleatória)
- Prática no TAIPA
O que é um modelo?
Um modelo é uma versão simplificada do mundo real.
Usamos modelos o tempo todo, mesmo sem perceber!
- George Box, estatístico
Modelos do dia a dia
Um mapa é um modelo do território
Uma planta baixa é um modelo de uma casa
Tipos de modelos
- Conceitual: desenho que explica um sistema (ex: ciclo da água)
- Físico: miniatura ou réplica (ex: maquete)
- Matemático: equações (ex: crescimento de árvore)
- Computacional: simulações no computador (ex: onde uma planta pode viver)
O que é um algoritmo?
Um algoritmo é um passo a passo para resolver um problema.
Pense como uma receita: você segue as instruções na ordem certa e chega ao resultado.
Algoritmos do dia a dia

Uma receita de bolo

Instruções para montar um móvel
Exemplo simples: calcular uma média
Para as notas [7, 8, 6, 9]:
- Soma: 7 + 8 + 6 + 9 = 30
- Média: 30 / 4 = 7,5
Algoritmos de computador seguem a mesma lógica, só que com muito mais dados!
Por que modelar onde as espécies vivem?
Cada espécie precisa de condições ambientais específicas: temperatura, chuva, solo...
O que queremos descobrir?
E a pergunta mais importante:
E na prática do engenheiro florestal?
Essas previsões ajudam vocês a tomar decisões reais:
- Restauração florestal: quais espécies plantar hoje que ainda vão sobreviver daqui a 30 anos?
- Plantios comerciais: onde plantar Pinus ou Eucalyptus considerando o clima futuro?
- Conservação: quais áreas proteger para salvar espécies ameaçadas?
- Manejo florestal: como adaptar planos de manejo se as espécies mudam de lugar?
De onde vêm os dados?
Para criar nosso modelo, precisamos de dois tipos de informação:
1 Onde a espécie foi encontrada
GBIF - banco de dados mundial de biodiversidade
- Reúne registros de museus, herbários e pesquisas
- Cada registro tem coordenadas (latitude e longitude)
Um mapa gigante com todos os locais onde alguém já encontrou cada espécie.
2 Condições ambientais de cada lugar
WorldClim - 19 variáveis climáticas globais
- Temperatura média do ano, do mês mais frio, do mais quente...
- Chuva total do ano, do mês mais seco, do mais chuvoso...
Com esses dados, sabemos as condições de temperatura e chuva em cada ponto do Brasil.
Analogia: o Detetive Ambiental
Vamos pensar no modelo como um detetive investigando onde uma planta gosta de viver.
1 Coletando pistas

O detetive visita locais onde a planta foi encontrada e anota:
- Quanto chove?
- Qual a temperatura?
- Qual a altitude?
2 Descobrindo padrões

Depois de visitar muitos locais, o detetive percebe:
3 Fazendo previsões

Agora, mesmo sem visitar um lugar novo, o detetive consegue dizer:
4 Reconhecendo limitações

O detetive sabe que não é perfeito. Ele pode não ter considerado competição entre plantas, tipo de solo, dispersores...
"Todos os modelos estão errados, mas alguns são úteis."
Aprendizado de Máquina
Em vez de nós dizermos as regras ao computador, ele descobre as regras sozinho olhando os dados.
Como funciona?
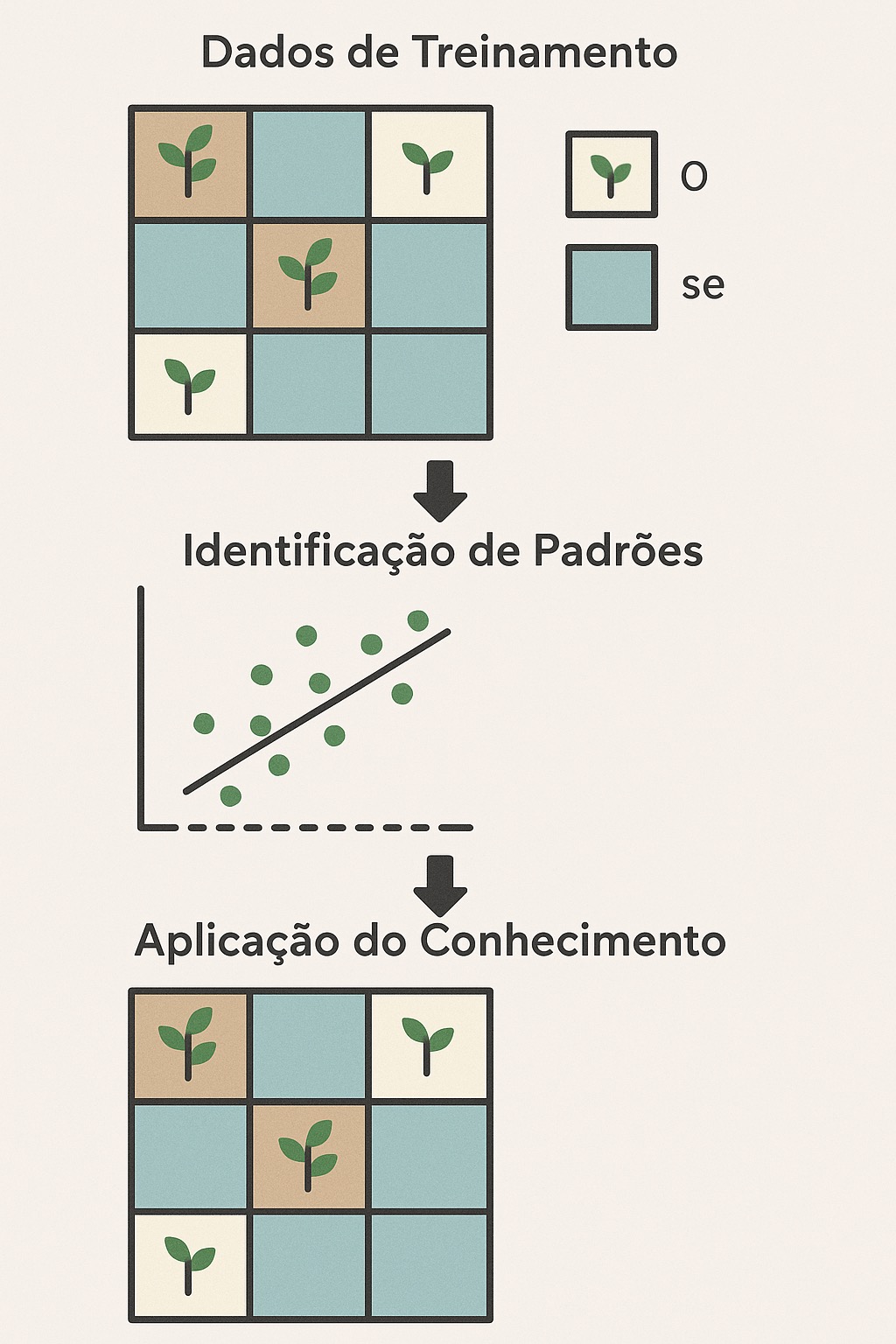
- Mostramos exemplos:
locais com e sem a espécie - O computador encontra padrões:
"nos locais com a espécie, a temperatura era entre X e Y" - Fazemos previsões:
para lugares novos que ele nunca viu
Árvore de Decisão
Funciona como um jogo de perguntas de sim ou não.
Cada pergunta divide os dados em dois grupos, até chegar a uma resposta.
Exemplo: a planta vive aqui?
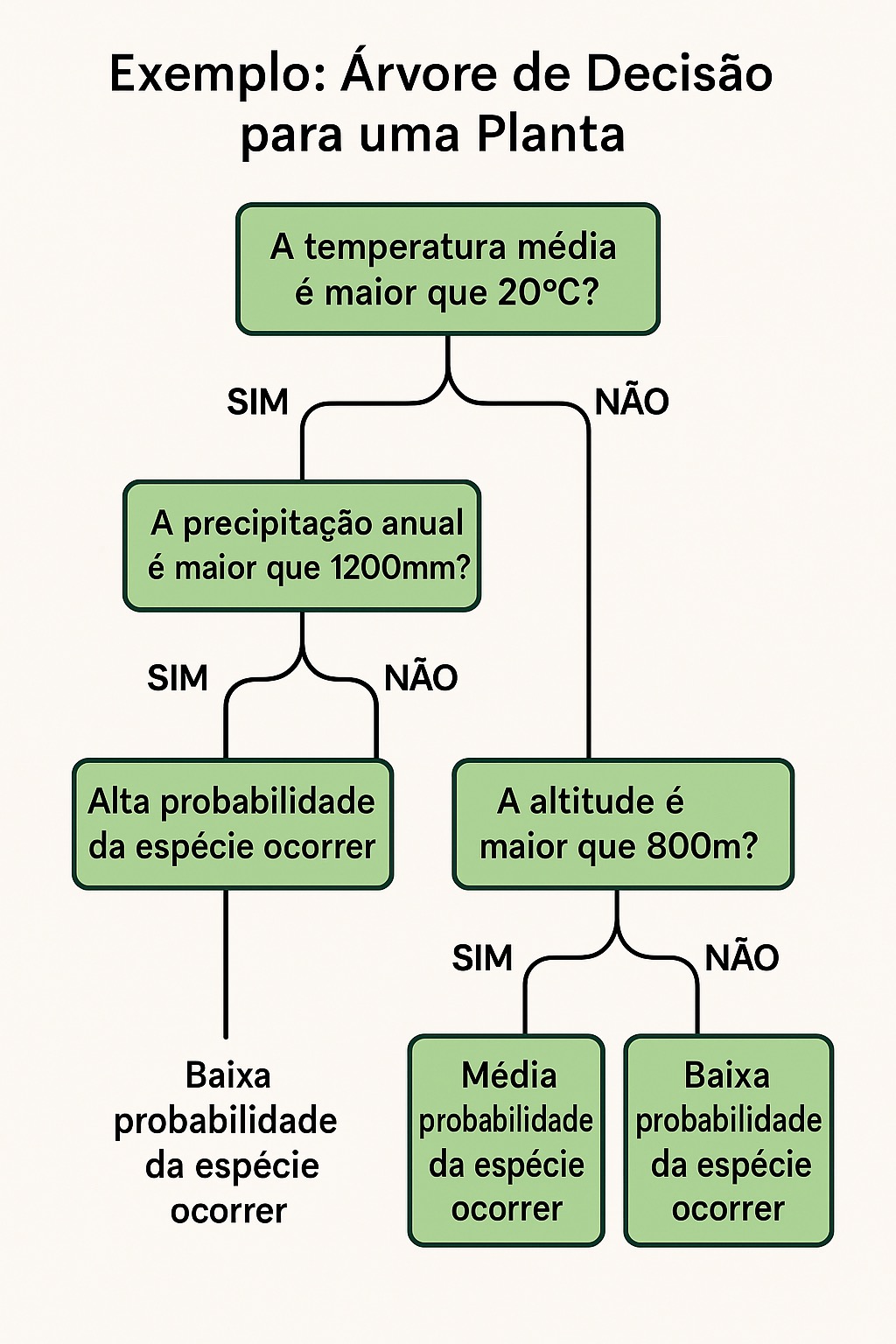
Temperatura > 20 graus?
├── SIM: Chove > 1200 mm?
│ ├── SIM: Provavelmente VIVE aqui
│ └── NÃO: Provavelmente NÃO vive
└── NÃO: Altitude > 800 m?
├── SIM: Talvez viva aqui
└── NÃO: Provavelmente NÃO vive
Cada "pergunta" usa uma variável ambiental para dividir os dados. É como um fluxograma!
Random Forest
"Floresta Aleatória" - é um algoritmo que cria muitas árvores de decisão e combina os resultados de todas elas.
Por que não usar só uma árvore?

Uma árvore sozinha pode:
- "Decorar" os dados em vez de aprender padrões reais
- Dar respostas muito diferentes se mudarmos poucos dados
Uma floresta de árvores diferentes dá respostas mais confiáveis!
Como funciona
- Cria muitas árvores (100+), cada uma um pouco diferente
- Cada árvore recebe dados e variáveis diferentes
- Cada árvore vota: "a espécie vive aqui? Sim ou não?"
- Resultado final: maioria dos votos vence, como numa eleição!
Analogia: equipe de detetives
Random Forest é como ter uma equipe de detetives em vez de só um:
O trabalho da equipe

- Cada detetive recebe pistas diferentes
- Cada um investiga do seu jeito
- Para decidir, fazemos uma votação
- A resposta do grupo é mais confiável do que a de um só
Por que o Random Forest é bom?
- Acerta bastante: votação entre árvores dá resultados mais precisos
- Resiste a erros: a maioria das árvores compensa dados ruins
- Mostra o que importa: quais variáveis foram mais relevantes
- Versátil: funciona com diferentes tipos de dados
Ajustes do Random Forest
O algoritmo tem alguns "botões de ajuste" que podemos configurar.
Vamos ver os três mais importantes:
Número de árvores
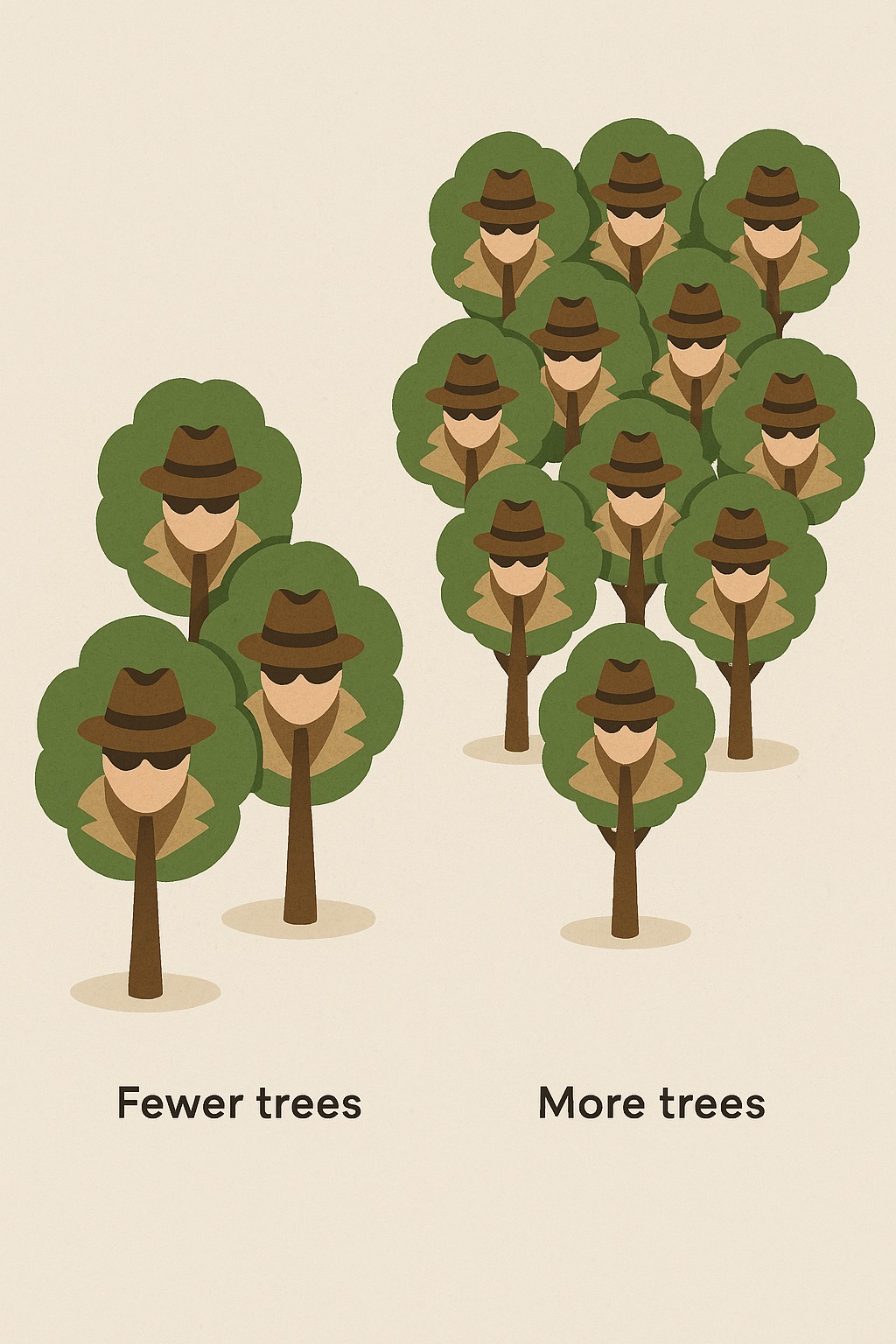
"Quantos detetives na equipe?"
- Mais árvores = resultado mais estável
- Mais árvores = demora mais para calcular
- Valor comum: 100 a 500
Profundidade das árvores
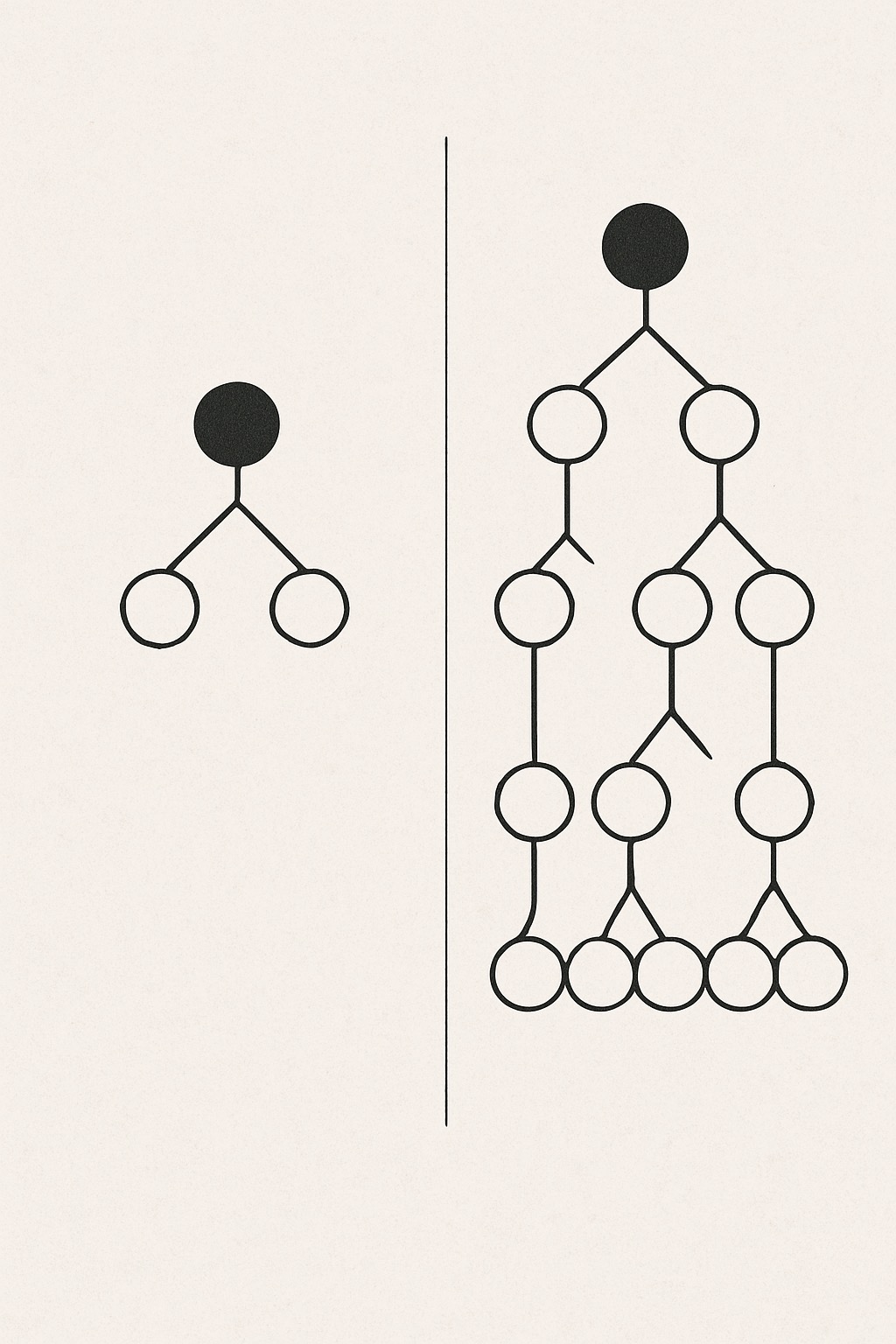
"Quantas perguntas cada detetive pode fazer?"
- Mais perguntas = mais detalhes
- Perguntas demais = risco de "decorar" em vez de aprender
- É preciso encontrar o equilíbrio!
Dados de treino vs. dados de teste
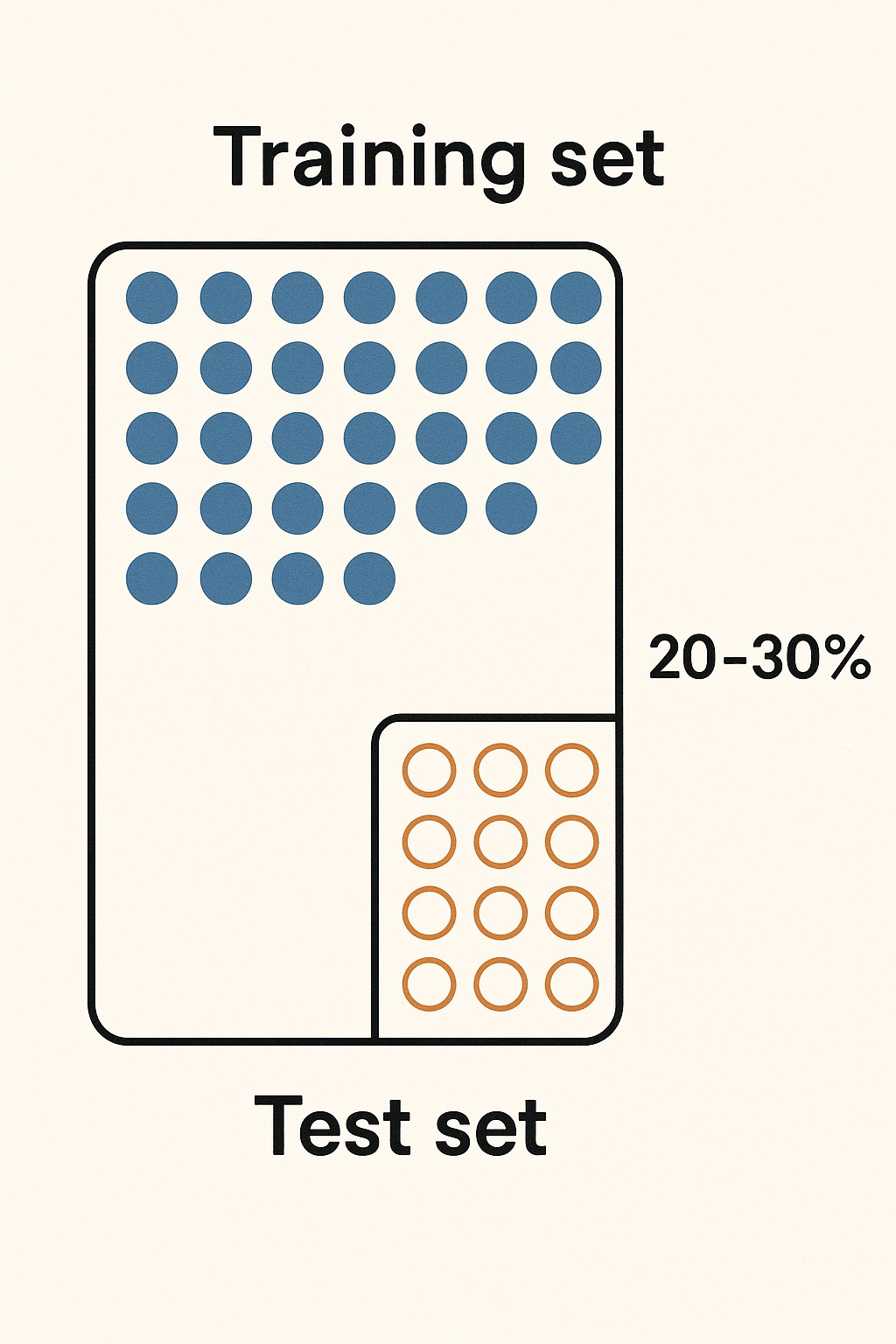
"Guardar uma prova para ver se o modelo acerta"
- Usamos 70-80% dos dados para ensinar o modelo
- Guardamos 20-30% para testar se ele realmente aprendeu
- Isso evita que o modelo "cole na prova"!
E no trabalho do engenheiro florestal?
Modelagem de distribuição é uma ferramenta profissional real, usada em:
Restauração ecológica
- O modelo indica quais espécies têm aptidão climática para aquele local
- Com a projeção futura, evita plantar espécies que vão perder habitat em 30 anos
Ex: se a Araucaria angustifolia vai perder área com o aquecimento, vale considerar espécies complementares.
Silvicultura e plantios
- Modelos ajudam a prever aptidão de espécies comerciais em cenários futuros
- Regiões que hoje são ótimas para Eucalyptus podem não ser em 2050
- Migração de zonas aptas pode abrir novas oportunidades
Licenciamento e consultoria ambiental
- Estudos de impacto ambiental (EIA) usam SDM para avaliar riscos
- Mapas de distribuição potencial embasam planos de compensação
- Órgãos ambientais cada vez mais exigem esse tipo de análise
Unidades de conservação
- Modelos identificam áreas de refúgio climático para espécies ameaçadas
- Ajudam a planejar corredores ecológicos entre fragmentos
- Priorizam regiões onde a proteção terá mais resultado a longo prazo
Hora da prática: TAIPA
Agora vamos aplicar tudo isso na plataforma TAIPA!
O que vamos fazer no TAIPA
- 1 Buscar espécie - baixar pontos de ocorrência
- 2 Pseudo-ausências - pontos onde a espécie NÃO está
- 3 Variáveis climáticas - selecionar as mais relevantes
- 4 Treinar modelo - ensinar o Random Forest
- 5 Mapa atual - onde a espécie pode viver hoje
- 6 Projeção futura - e com a mudança climática?
O que aprendemos hoje
- Modelo = versão simplificada da realidade
- Algoritmo = passo a passo para resolver um problema
- Aprendizado de máquina = o computador descobre padrões nos dados
- Random Forest = muitas árvores de decisão votando juntas
- Modelagem de distribuição = prever onde uma espécie pode viver, hoje e no futuro
Próximos passos
- Executar modelos no TAIPA
- Interpretar os mapas de distribuição
- Comparar cenários de mudança climática
- Discutir: o que fazer com esses resultados na prática?